Screaming Frog SEO Spider Tool – Hướng dẫn chi tiết cách Audit Website
Screaming Frog SEO Spider Tool là gì?
Screaming Frog SEO Spider là một công cụ kiểm toán trang web – Site Audit nó có thể được sử dụng để thu thập dữ liệu cả các trang web nhỏ và các trang web lớn, nó có tốc độ quét siêu nhanh và bạn có thể sử dụng công cụ này trên bất kỳ nên tảng nào như Windows, MacOS hay Linux. SEO Tool này đang được hàng ngàn SEOer và các công ty trên toàn thế giới tin tưởng sử dụng để kiểm tra các vấn đề về kỹ thuật SEO cho trang web của họ.
Screaming Frog SEO Spider là một trình thu thập dữ liệu trang web giúp bạn cải thiện các vấn đề SEO tại chỗ, bạn có thể trích xuất dữ liệu và thực hiện việc kiểm toán các vấn đề SEO phổ biến. Ở bản miễn phí bạn có thể tải xuống và thu thập dữ liệu 500 URL, nhưng nếu bạn không muốn bị hạn chế các tính năng thì bạn nên mua bản quyền phần mềm để có thể truy cập các tính năng nâng cao.
Bạn có thể làm gì với SEO Spider Tool?
SEO Spider cho phép bạn phân tích kết quả theo thời gian thực ví dụ như bạn có thể biết được trang nào đang chuyển hướng 301, 302, trang nào đang thiếu thẻ meta như title hay description hoặc bạn có thể biết được trang nào đang bị trùng lặp. Bạn có thể xem, phân tích và lọc dữ liệu đã thu thập được ngay trong giao diện của chương trình.
SEO Spider cho phép bạn Export dữ liệu như (URL, page title, meta description, headings etc) sang bản tính excel và từ đó giúp bạn có cái nhìn bao quát hơn các vấn đề về SEO trong trang web.
Làm thế nào để thu thập dữ liệu toàn bộ trang web
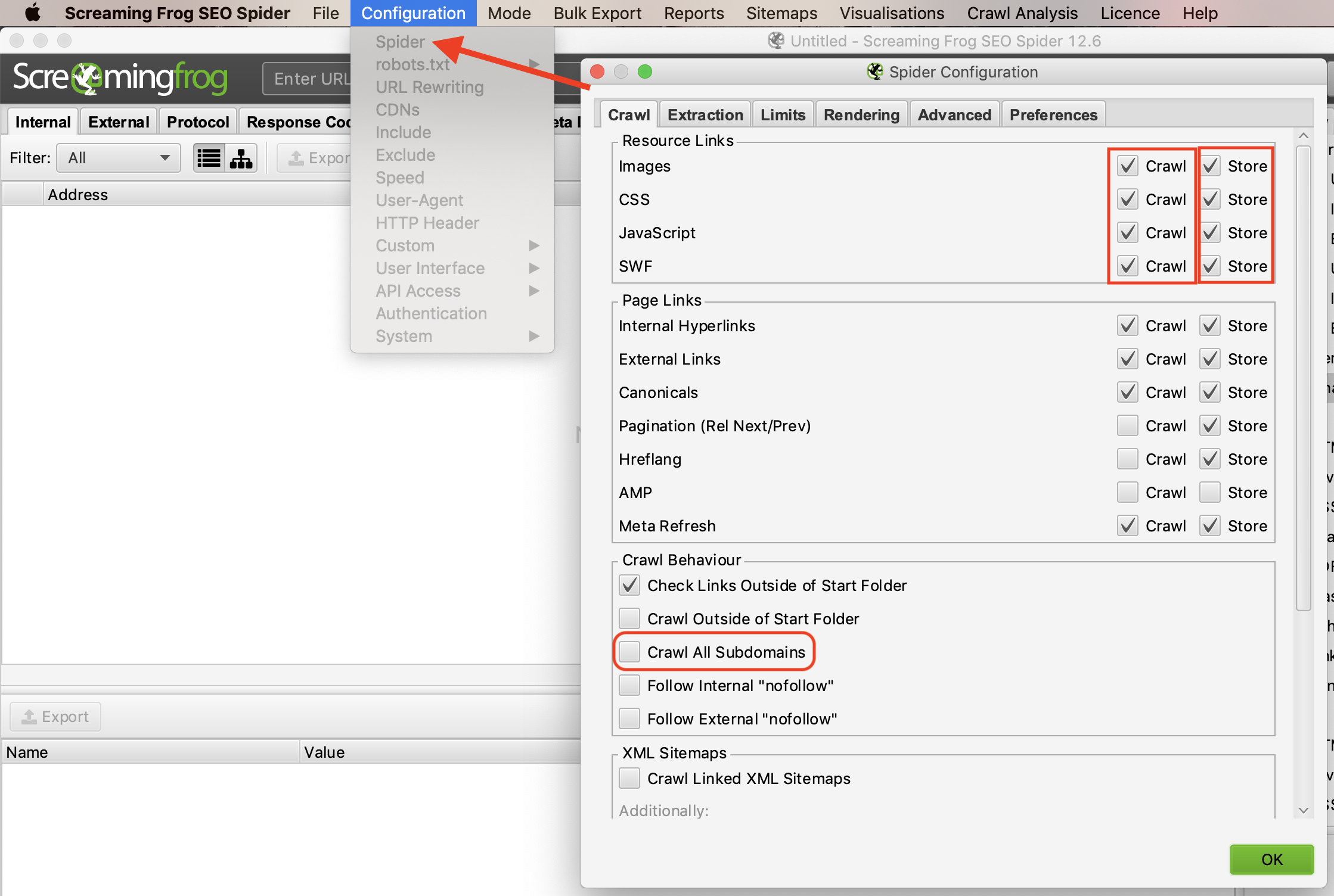
Khi bắt đầu thu thập thông tin, bạn nên dành một chút thời gian và đánh giá thông tin bạn muốn nhận là gì, trang web lớn như thế nào và cần thu thập dữ liệu bao nhiêu trang web? Đôi khi, với các trang web lớn, bạn có thể hạn chế trình thu thập thông tin không quét một danh mục nào đó. Điều này giữ cho kích thước tệp khi xuất ra có dung lượng nhỏ và dễ xem xét dữ liệu. Để thu thập dữ liệu toàn bộ trang web của bạn, bao gồm tất cả các tên miền phụ Sub domain, bạn sẽ cần thực hiện một số điều chỉnh nhỏ trong cấu hình.
Bởi vì mặc định, Screaming Frog chỉ thu thập tên miền phụ mà bạn nhập. Ví dụ bạn có tên miền abc.com và tên miền phụ là xyz.abc.com và khi bạn nhập tên miền abc.com vào để quét thông tin thì Screaming Frog sẽ coi xyz.abc.com là liên kết bên ngoài. Để thu thập dữ liệu cả tên miền chính và tên miền phụ đó bạn phải thay đổi cài đặt trên thanh menu chọn “Configuration” và chọn “Spider” sau đó click vào “Crawl All Subdomains”.
Bạn có thể sử dụng cú pháp tìm kiếm nâng cao trên Google để kiểm tra tên miền phụ: site:tenwebmuonkiemtra.com -inurl:tenwebmuonkiemtra.com
Ngoài ra, bạn cũng nên click vào ô “Crawl Outside of Start Folder” để thu thập thông tin tất cả các thư mục và thư mục con. Để tiết kiệm thời gian quét và giảm dung lượng khi xuất files, bạn hãy chú ý đến các tài nguyên mà bạn có thể không cần trong quá trình thu thập dữ liệu của mình. Theo mặc định, Screaming Frog được thiết lập để thu thập tất cả các dữ liệu như hình ảnh, JavaScript, CSS và các tệp flash, nếu bạn muốn chỉ thu thập dữ liệu HTML, bạn sẽ phải bỏ chọn CSS, JavaScript và SWF.
Làm thế nào để thu thập dữ liệu một danh mục hoặc danh mục con trên website
Nếu bạn muốn chỉ thu thập thông tin của một thư mục, hãy chọn “Crawl Outside of Start Folder” và bây giờ bạn chỉ cần nhập URL và nhấn Start.
Làm thế nào để không thu thập dữ liệu của một danh mục hoặc danh mục con
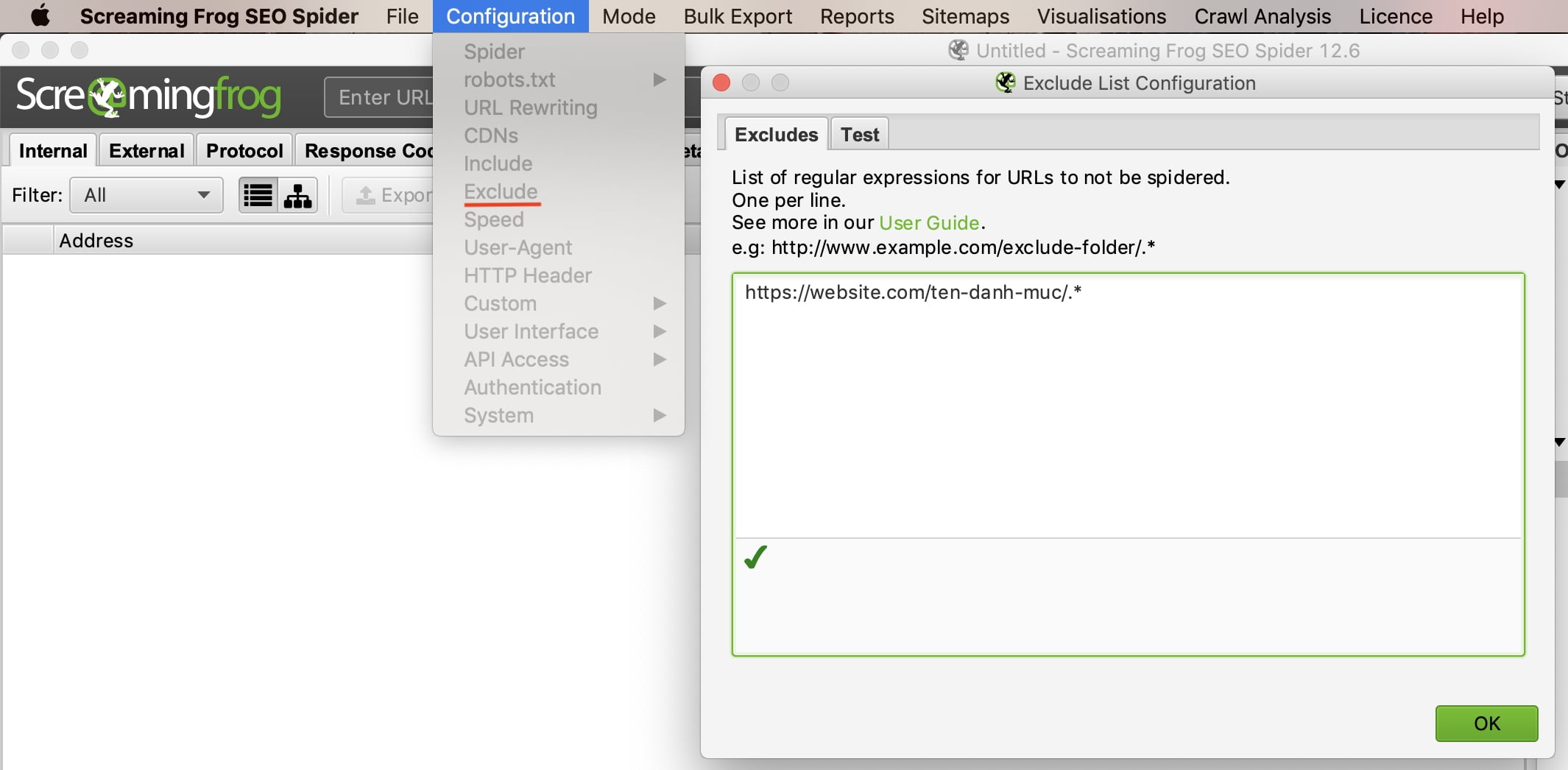
Trong ví dụ này, chúng tôi đã thu thập mọi dữ liệu trang website.com ngoại trừ các bài viết trong danh mục “ten-danh-muc”. Bây giờ bạn hãy click vào tab “Test” để kiểm tra. Đây là giải pháp tốt để thu thập dữ liệu các website lớn.
Sau khi thu thập thông tin kết thúc, hãy chuyển đến tab “Internal” điều kiện lọc chọn “HTML”. Nhấp vào “Export”, và bạn sẽ có danh sách đầy đủ ở định dạng CSV.

Nếu bạn muốn lưu lại cấu hình đã cài đặt đó bạn chọn: File –> Configuration –> Save As…
Cách thu thập dữ liệu trang web thương mại điện tử hoặc trang web lớn khác
Phiên bản mới nhất của Screaming Frog đã được cập nhật để dựa vào cơ sở dữ liệu mà nó đang lưu trữ để thu thập dữ liệu. Screaming Frog phiên bản mới nhất cho phép người dùng chọn lưu tất cả dữ liệu vào ổ cứng thay vì chỉ giữ nó trong RAM. Điều này đã mở ra khả năng thu thập dữ liệu các trang web rất lớn cho những người có nhu cầu.
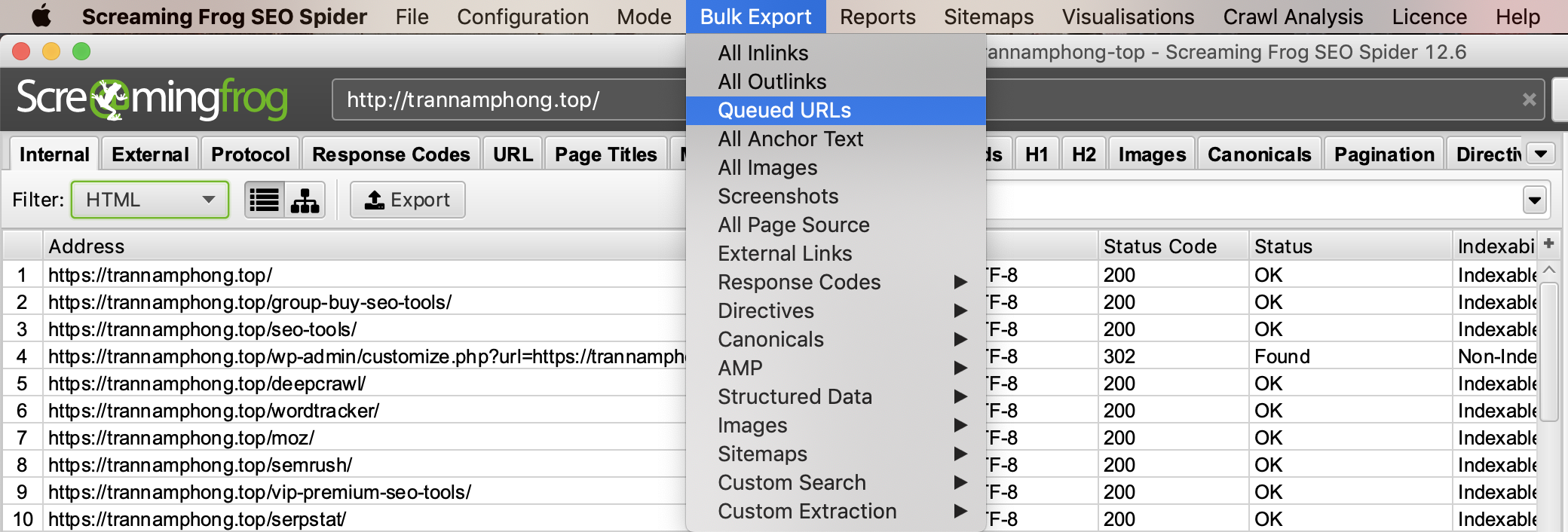
Làm thế nào để chạy phần mềm Screaming Frog mà không bị sập không bị crash
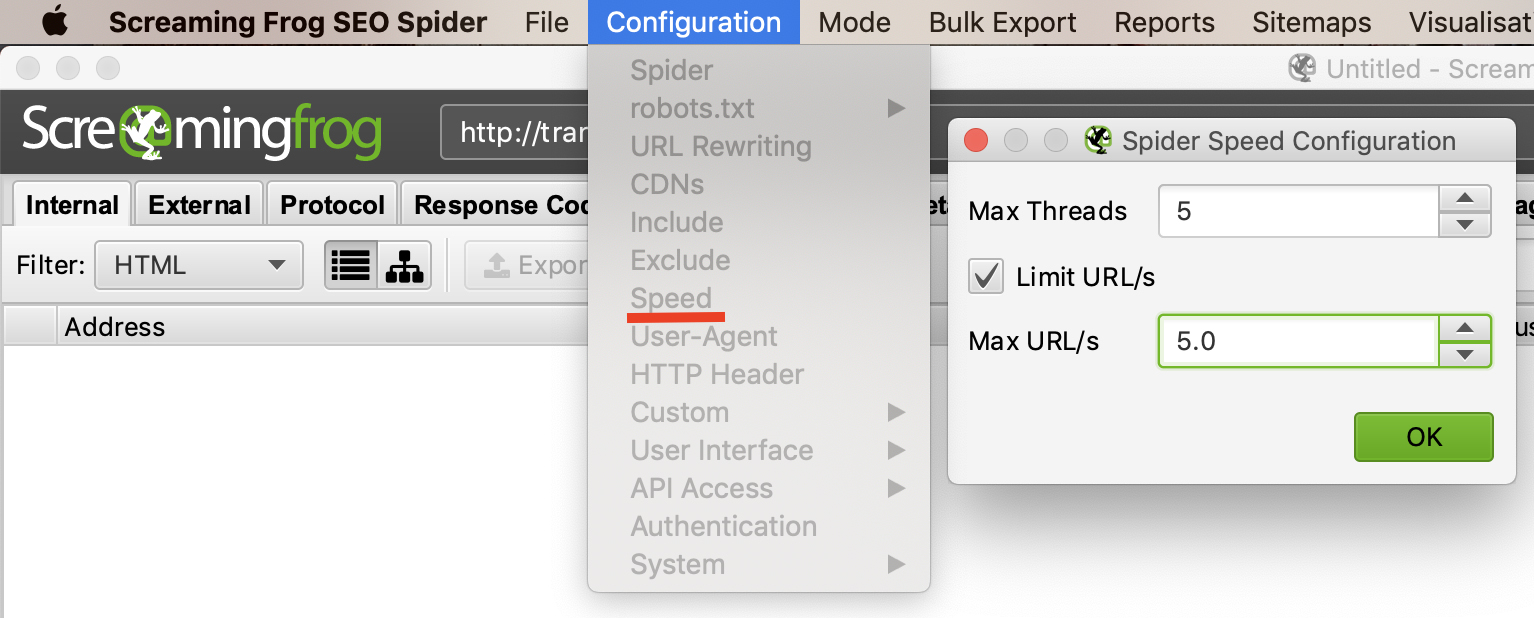
Nếu bạn thu thập dữ liệu của trang web đang lưu trữ trên mấy chủ công nghệ cũ thì có thể máy chủ đó không đáp ứng để sử lý được tốc độ quét quá nhanh của Screaming Frog. Hoặc cũng có thể máy chủ đó hạn chế việc quét và thu thập dữ liệu của trang web. Chúng tôi khuyên bạn nên đặt giới hạn số lượng URL mà bạn muốn quét/giây bởi vì với các website lớn họ có hệ thống tường lửa nên họ có thể chặn địa chỉ IP của bạn nếu bạn để tốc độ quét quá nhanh, đây cũng có thể coi là DDOS nên tường lửa có thể chặn các truy cập này.
Để thay đổi tốc độ thu thập dữ liệu của bạn, hãy chọn “Speed” trong phần menu “Configuration” và trong cửa sổ mở lên, chọn số lượng luồng tối đa sẽ chạy đồng thời. Từ menu này, bạn cũng có thể chọn số lượng URL tối đa được yêu cầu mỗi giây.
Nếu bạn thấy rằng việc thu thập dữ liệu của mình hiển thị nhiều lỗi máy chủ web, hãy chuyển đến tab “Advanced” trong menu “Spider Configuration” và tăng giá trị của “Response Timeout” và “5xx Response Retries” để xem kết quả tốt hơn không.
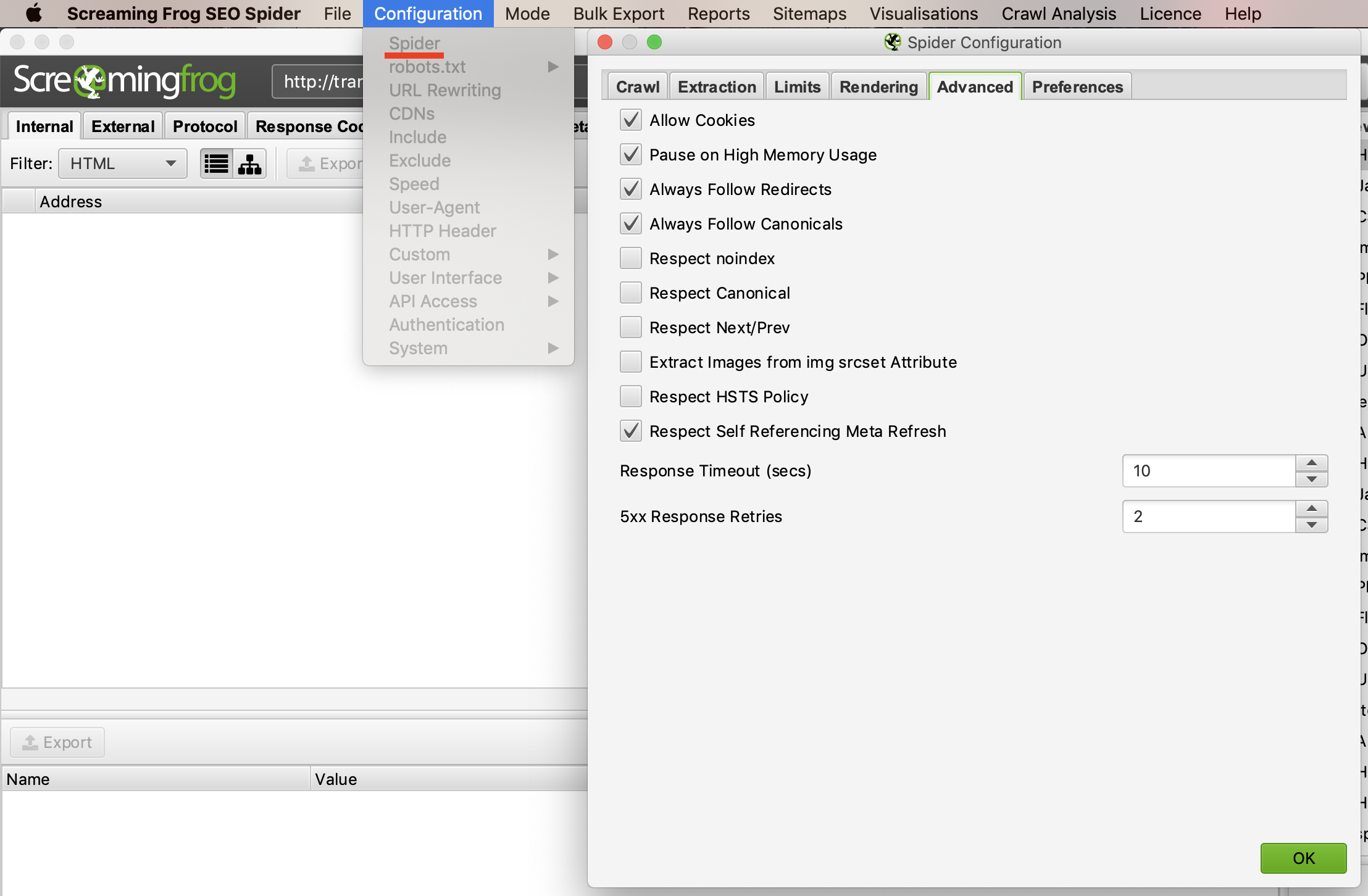
Để đảm bảo việc thu thập thông tin không bị lỗi bạn nên click chọn “Allow Cookies”
Cách thu thập dữ liệu bằng cách sử dụng một tác nhân người dùng khác
Để thu thập dữ liệu bằng cách sử dụng một tác nhân người dùng khác, chọn “User-Agent” trong phần menu “Configuration”, sau đó chọn bot tìm kiếm từ trình đơn thả xuống hoặc nhập chuỗi tác nhân người dùng mà bạn biết.
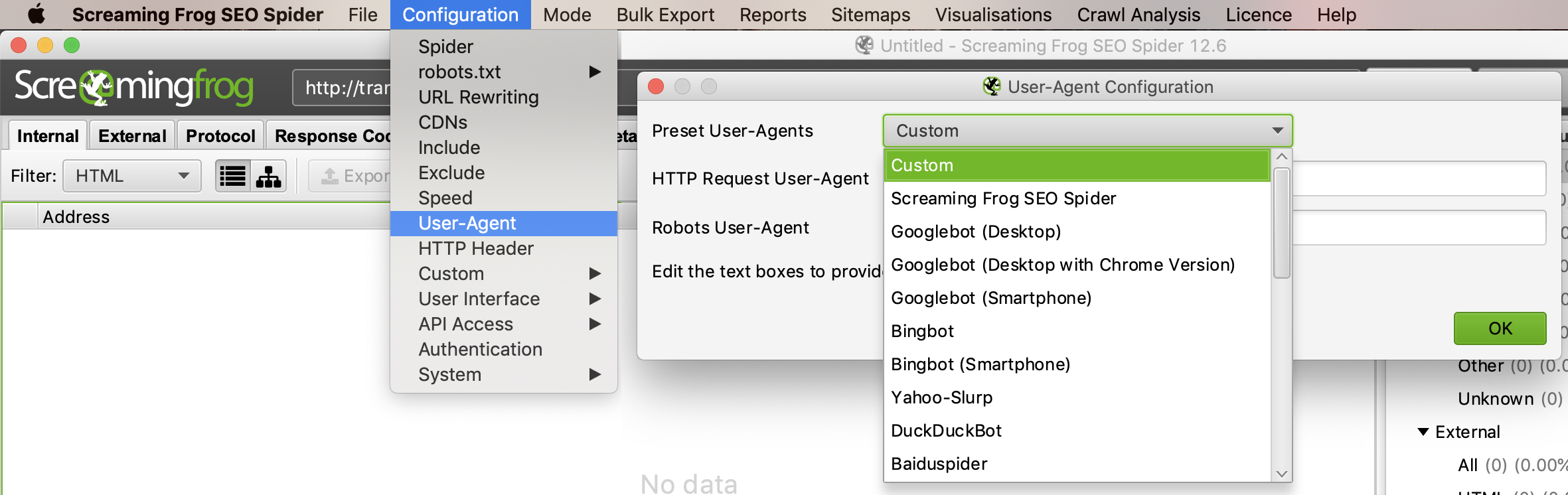
Hiện tại Google cũng sử dụng 2 tác nhân người dùng User-Agent khi đi Crawl dữ liệu: Một là User-Agent Smartphone và 2 là User-Agent Desktop. Điều này rất quan trọng vì 2 lý do dưới đây.
Thu thập dữ liệu trang web bắt chước tác nhân người dùng điện thoại thông minh sẽ giúp Googlebot xác định các sự cố mà Google có thể sẽ gặp phải khi thu thập dữ liệu và nội dung hiển thị trên trang web của bạn.
Sử dụng phiên bản User-Agent khác như Desktop giúp Googlebot phân biệt giữa thu thập thông tin từ điện thoại và thu thập thông tin bằng máy tính khi phân tích nhật ký trong máy chủ.
Có lẽ Google sử dụng 2 dạng User-Agent khi đi Crawl hay Index website sẽ giúp Google đánh giá xem website đó có thân thiện với các thiết bị di động hay không.
Làm thế nào để quét các trang web yêu cầu xác thực việc đăng nhập
Khi Screaming Frog SEO Spider bắt gặp một trang được bảo vệ bằng mật khẩu, sẽ có 1 cửa sổ pop-up xuất hiện, và bạn cần nhập thông tin như Username Password nếu muốn thu thập thông tin trong đó.
Xác thực dựa trên biểu mẫu là một tính năng rất mạnh mẽ và có thể yêu cầu hiển thị JavaScript để hoạt động hiệu quả. Lưu ý: Xác thực dựa trên biểu mẫu nên được sử dụng một cách tiết kiệm và chỉ bởi người dùng nâng cao. Trình thu thập thông tin được lập trình để nhấp vào mọi liên kết trên một trang, do đó có khả năng dẫn đến các liên kết để đăng xuất bạn, tạo bài đăng hoặc thậm chí xóa dữ liệu.
Để quản lý xác thực, bạn chọn “Configuration” –>”Authentication”.
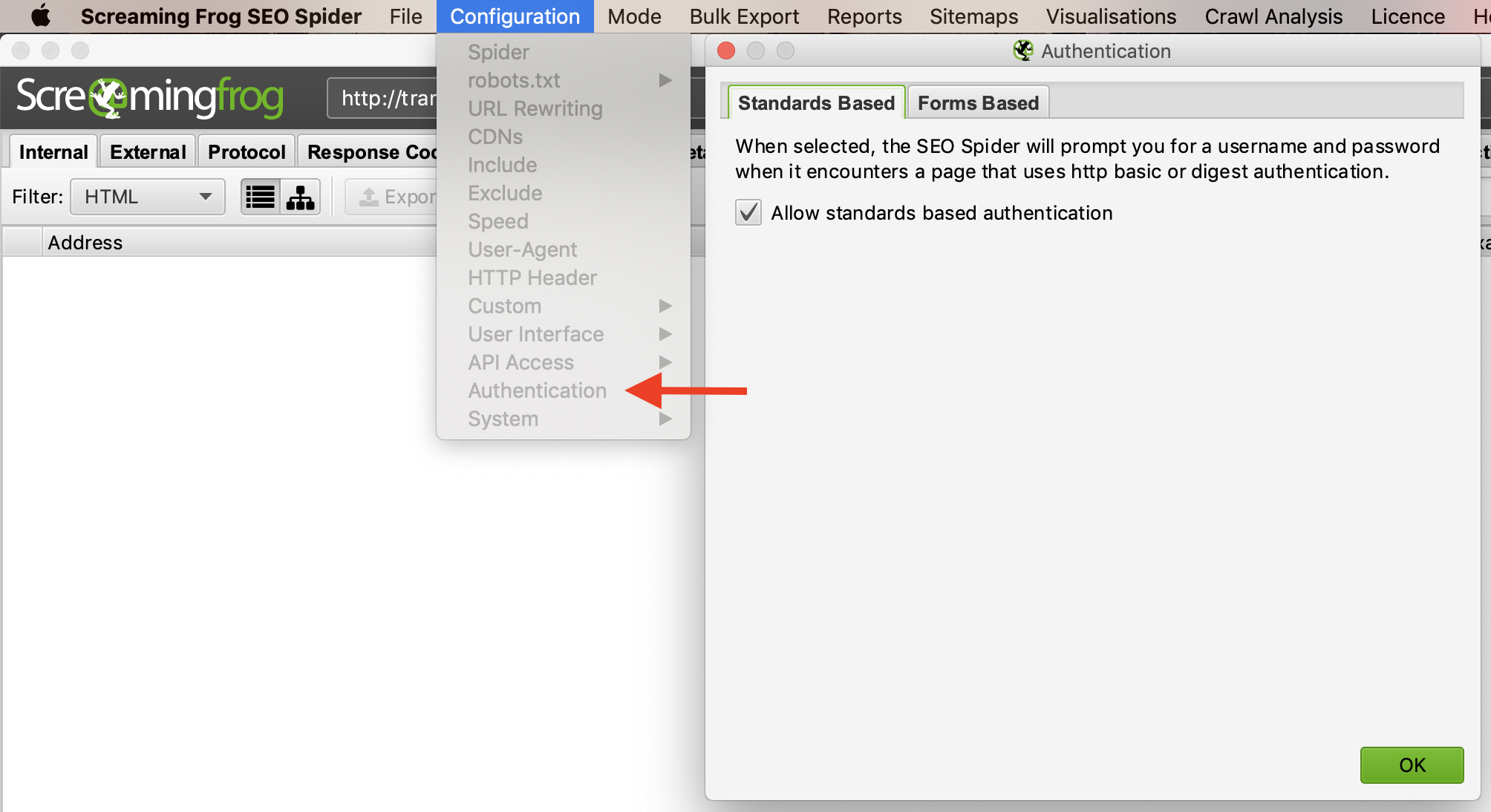
Để tắt yêu cầu xác thực, bỏ chọn “Allow Standards Based Authentication”
Làm thế nào để tìm các liên kết bị gãy trong 1 trang hoặc toàn trang
Nếu bạn không cần kiểm tra hình ảnh, JavaScript, Flash hoặc CSS trên trang web, hãy bỏ chọn các tùy chọn này trong menu Cấu hình Spider để tiết kiệm thời gian xử lý và bộ nhớ.
Khi “con nhện” đã hoàn thành việc thu thập thông tin, hãy sắp xếp Kết quả ở tab “Internal” theo “Status Code” như 404 hoặc 301…
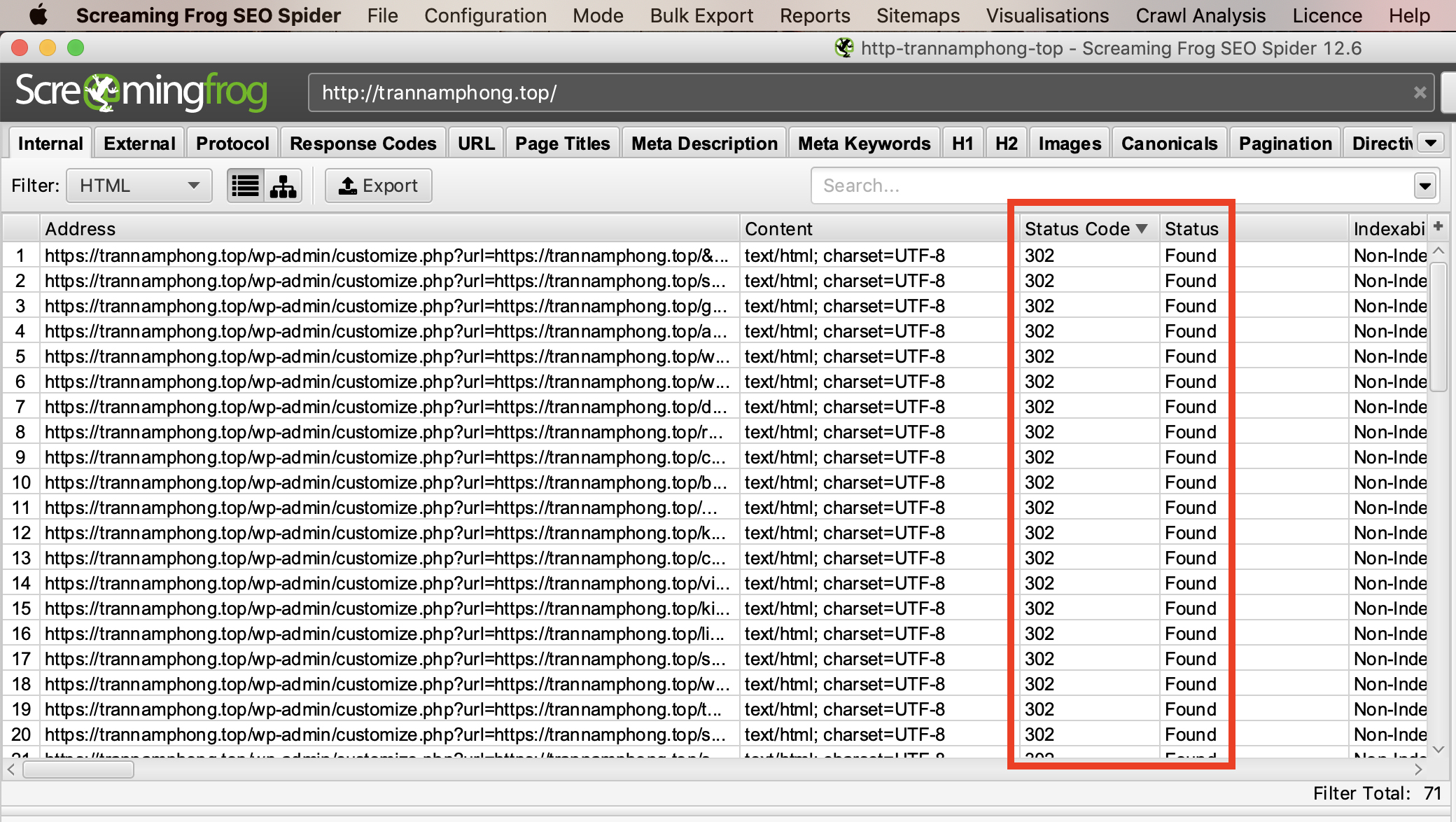
Hoặc bạn cũng có thể xem và Export các trang bị lỗi ở tab “Response Codes”
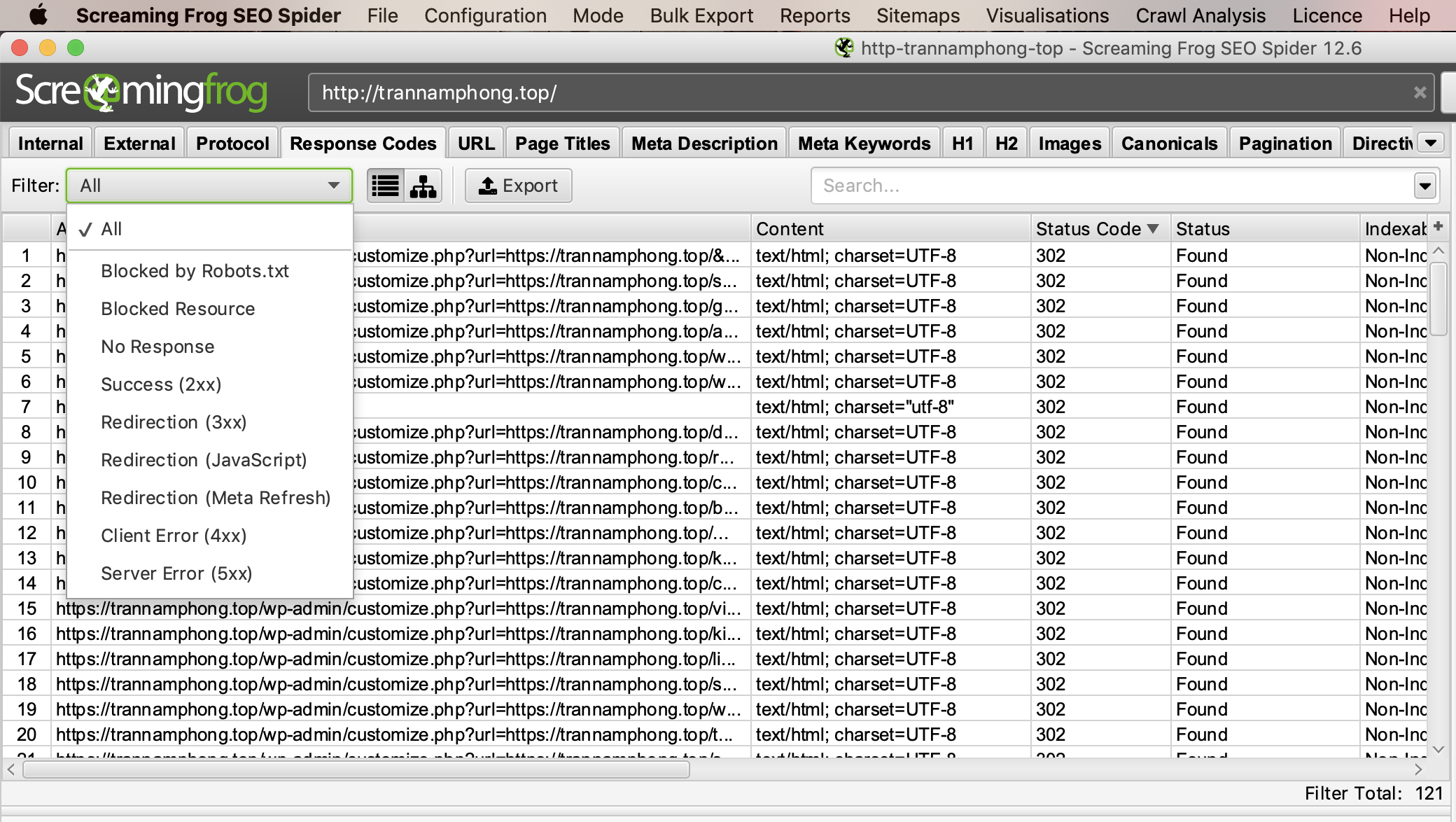
Để xuất danh sách đầy đủ các trang bao gồm các liên kết bị hỏng hoặc chuyển hướng, hãy truy cập menu “Bulk Export”. Cuộn xuống “Response Codes” và xem các báo cáo sau:
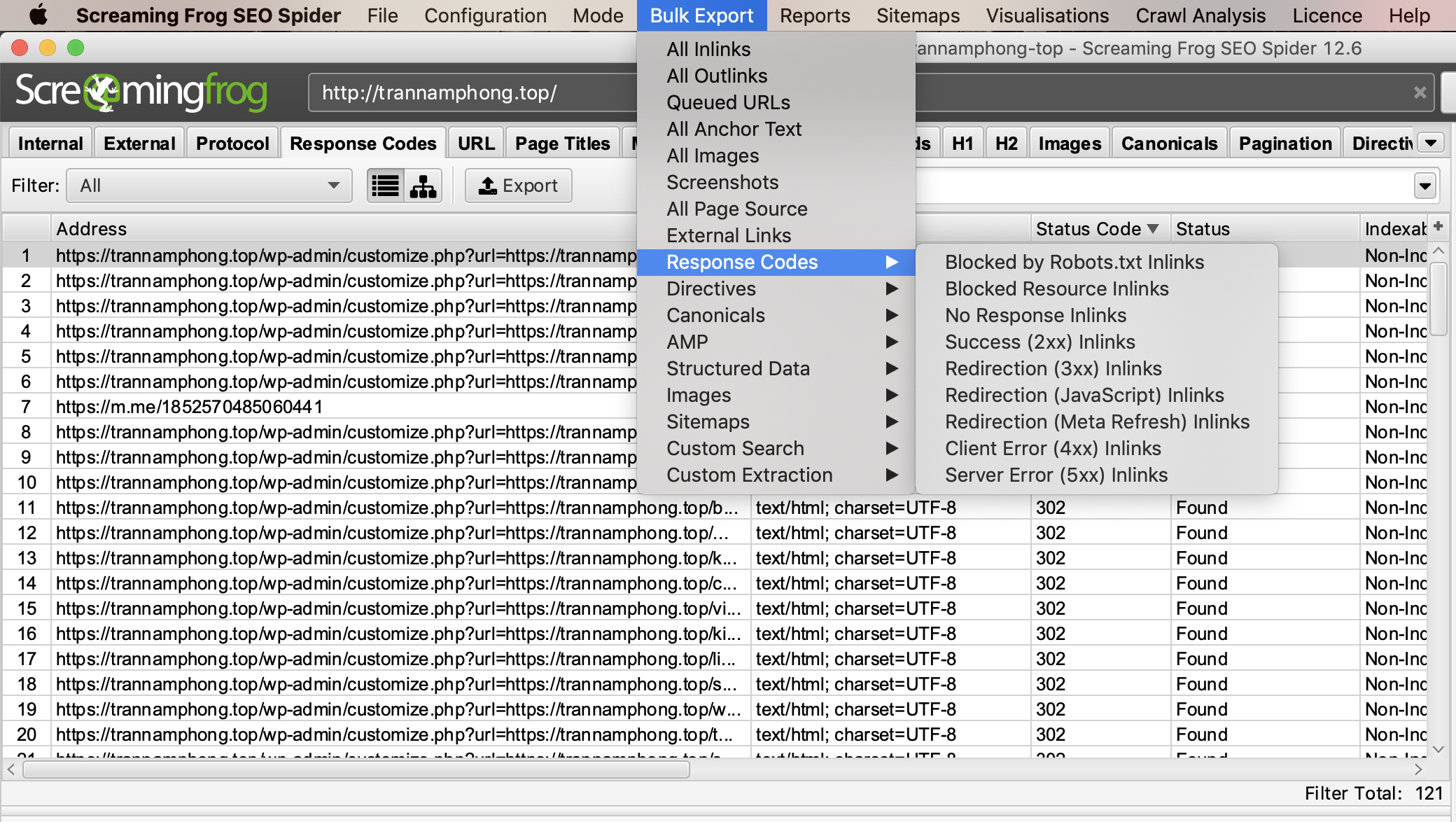
No Response Inlinks
Redirection (3xx) Inlinks
Redirection (JavaScript) Inlinks
Redirection (Meta Refresh) Inlinks
Client Error (4xx) Inlinks
Server Error (5xx) Inlinks
Việc xem xét những báo cáo này giúp chúng tôi có cái nhìn đầy đủ về các lỗi đang có trên trang web, từ đó giúp chúng tôi nhanh chóng khắc phục các sự cố.
Bạn có thể sử dụng Screaming Frog để tìm toàn bộ liên kết bị hỏng trên bất kỳ trang web nào mà bạn muốn sau đó liên hệ với chủ sở hữu trang web, đề xuất thay thế trang web của bạn cho liên kết bị hỏng nếu bài viết đó phù hợp với với chủ đề website của bạn.
Tìm tất cả các liên kết ra bên ngoài bị hỏng hoặn tìm tất cả các Outbound Links
Trên thanh menu chọn “Configuration” và chọn “Spider” sau đó click vào ô “External Links”. Sau khi Spider đã Finish thu thập thông tin click vào tab “External” trong cửa sổ phía trên bên tay trái và chọn sắp xếp theo “Status Code”. Bạn sẽ tìm thấy các mã lỗi ngoài mã 200. Bạn hãy nhấn vào URL bị lỗi và nhấn vào tab “In Links” ở cửa sổ dưới cùng, bạn sẽ tìm thấy danh sách các trang đang trỏ đến URL đã chọn. Bạn có thể sử dụng tính năng này để xác định các trang đang chỉ link đến các liên kết ngoài mà liên kết ngoài đó đang bị lỗi.
Để trích xuất toàn bộ danh sách bạn hãy chọn “Bulk Export” trên thanh menu và chọn “External Links”. Nếu bạn muốn xem cả Anchor text của Outbound link đó bạn hãy chọn “All Outlinks” trong menu “Bulk Export”.
Cách tìm các liên kết đang được chuyển hướng – Redirect
Sau khi quá trình thu thập thông tin kết thúc bạn hãy chọn tab “Response Codes” và lọc theo các mã trạng thái 301 | 302 | 307 Nhấp vào tab “In Links” ở cửa sổ dưới cùng để xem tất cả các trang sử dụng liên kết chuyển hướng.
Cách xác định các trang có nội dung mỏng – Thin Content
Sau khi đã hoàn tất thu thập thông tin, hãy chuyển đến tab “Internal”, lọc theo HTML, sau đó cuộn sang bên phải và dừng lại ở cột “Word Count”. Sắp xếp cột “Word Count” từ thấp đến cao để tìm các trang có ít nội dung văn bản. Bạn có thể kéo và thả cột “Word Count” sang trái để so sánh dữ liệu với các cột khác. Nhấp vào “Export” trong tab “Internal” nếu bạn muốn xem ở dạng CSV.
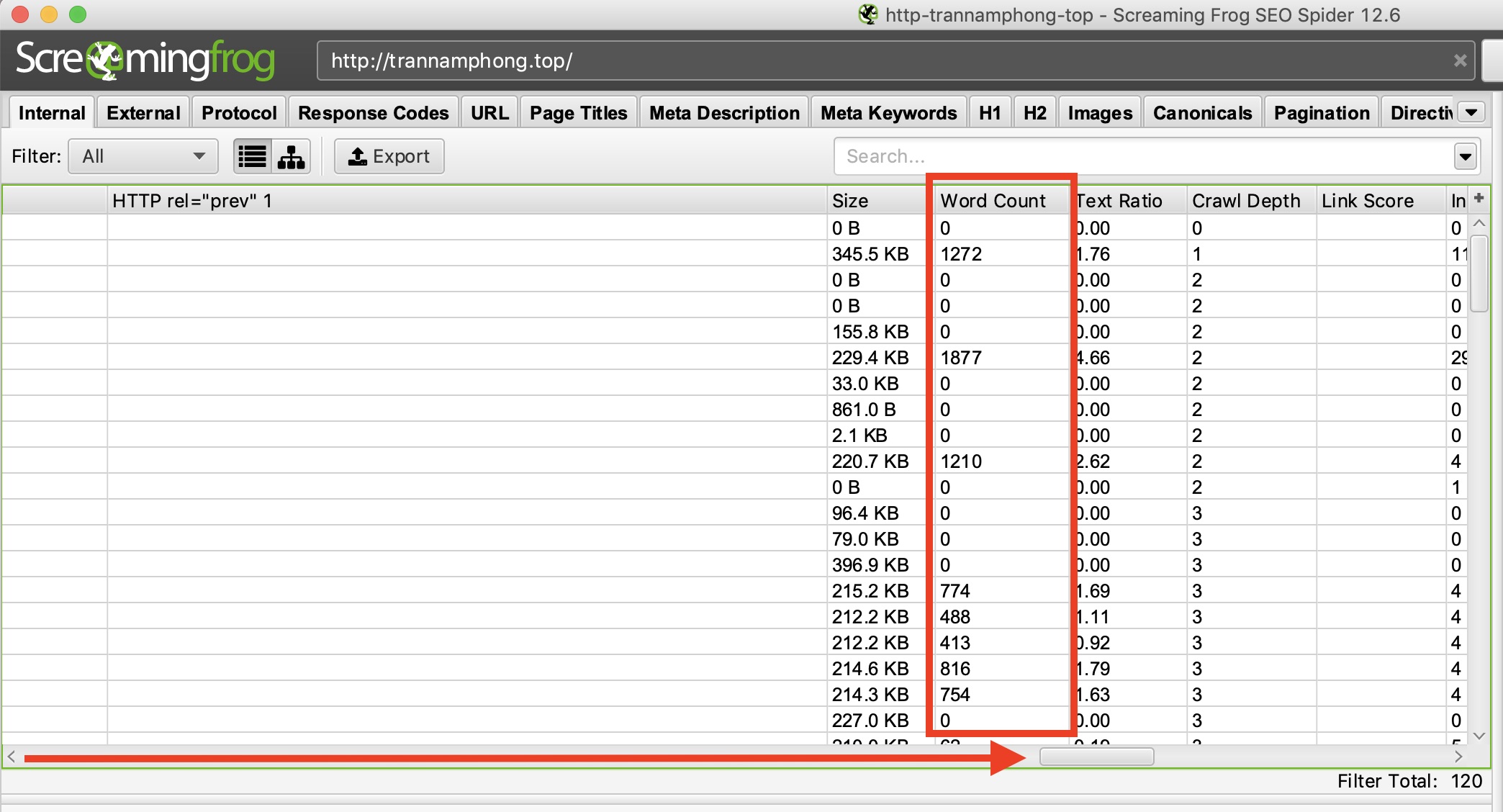
Mẹo tìm các bài viết ngắn trên các trang web thương mại điện tử web bán hàng:
Mặc dù phương pháp đếm từ ở trên sẽ định lượng văn bản thực tế trên trang, nhưng vẫn không có cách nào để biết liệu văn bản tìm thấy là tên sản phẩm hay là văn bản nằm trong phần nội dung. Để tìm ra số lượng từ của các khối văn bản của bạn, hãy sử dụng ImportXML2 của @iamchrisle để cào các khối văn bản trên bất kỳ danh sách các trang nào, sau đó đếm các ký tự từ đó. Bạn cũng có thể sử dụng tiện ích mở rộng xPath Helper hoặc Xpather trên trình duyệt Chrome để tìm các bài viết có nội dung ngắn và mỏng.
Tôi muốn một danh sách các liên kết hình ảnh trên một trang cụ thể
Nếu bạn đã thu thập dữ liệu toàn bộ trang web hoặc thư mục con, chỉ cần chọn trang mà bạn muốn xem đường link các hình ảnh có trong trang đó, sau đó nhấp vào tab “Image Details” ở cửa sổ dưới cùng để xem tất cả các hình ảnh được tìm thấy trên trang đó.
Cách tìm các hình ảnh thiếu thẻ Alt hoặc các hình ảnh có thẻ Alt quá dài
Đầu tiên, bạn cần đảm bảo rằng tã tích chọn “Check Images” trong menu Spider Configuration. Sau khi thu thập thông tin xong, hãy chuyển đến tab “Images” và Filter ‘Missing Alt Text’ hoặc ‘Alt Text Over 100 Characters’. Bạn có thể xem qua các trang này bằng cách click vào đường link các hình ảnh có trong trang đó, sau đó nhấp vào tab “Image Details” ở cửa sổ dưới cùng để xem thông tin.
Cuối cùng, bạn có thể xuất files CSV, hãy sử dụng menu chọn “Bulk Export” trên thanh menu và chọn “Images” sau đó chọn “Missing Alt Text” hoặc “Alt Text Over 100 Characters” để xem danh sách đầy đủ tất cả các hình ảnh như vị trí của chúng, văn bản thay thế và alt text.
Mẹo: Ở cột phía bên thay phải bạn cũng sẽ nhín thấy những thông tin đó bạn có thể click vào và lựa chọn thông tin mà bạn muốn xem.
Cách tìm các trang có tiêu đề mô tả hoặc đường link quá dài
Bạn hãy click vào tab “Page Titles” và chọn Filter by “Over 60 Characters”. Bạn có thể làm tương tự trong tab “Meta Description” hoặc trong tab “URL”
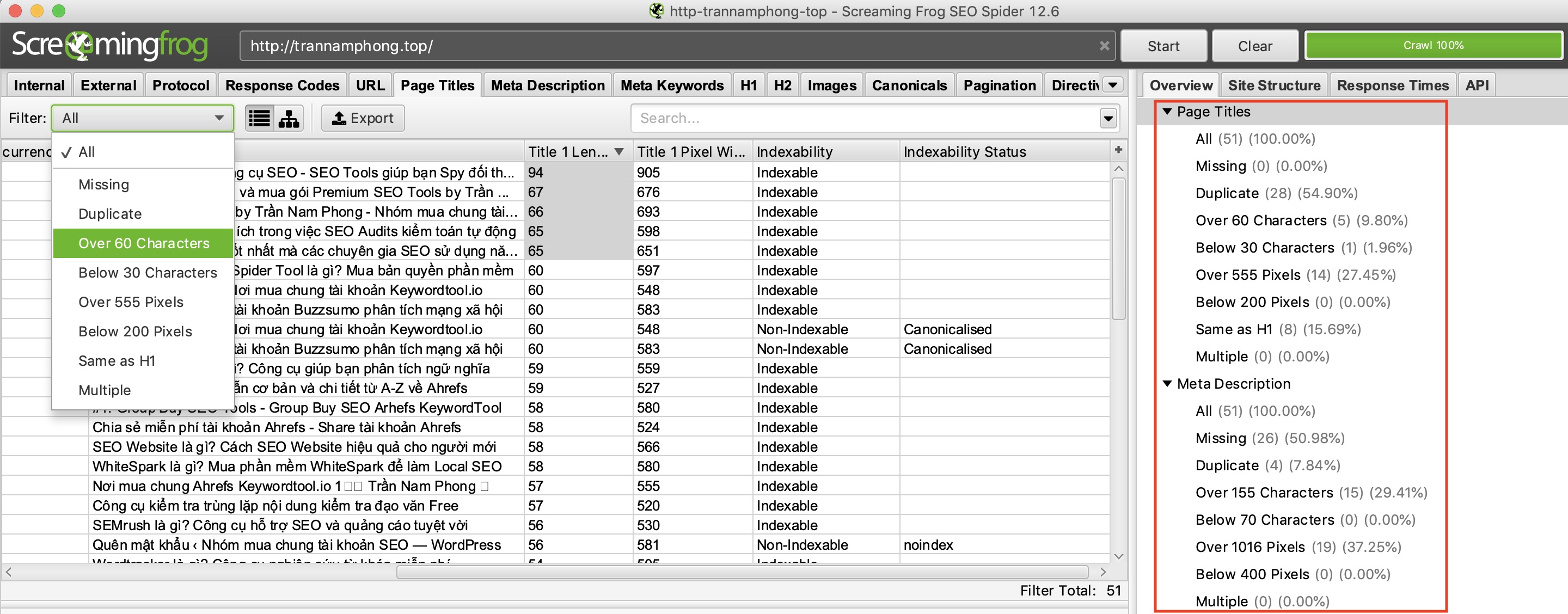
Ở đây bạn có thể tìm các trang bị trùng lặp tiêu đề, mô tả hoặc url nếu chọn Filter “Duplicate”. Bạn muốn lọc thông tin gì thì chọn tab đó và chọn “Duplicate”.
Cách nhận dạng các trang có thẻ meta: nofollow/noindex/noodp/canonical…
Nhấn vào tab “Directives”, cuộn sang bên phải để xem thông tin từ các cột. Bạn có thể chọn lọc thông tin Filter theo thẻ meta mà bạn muốn.
Mẹo: Khi Screaming Frog SEO Tools chạy xong nếu bạn muốn xem các thông tin thẻ Meta bạn hãy chọn chọn “Mode” –> “List”, sau đó tải lên danh sách URL của bạn ở định dạng .txt hoặc .csv và nhấn “Start” sau khi hoàn thành, bạn có thể xem mã trạng thái, liên kết ngoài, số từ trên mỗi bài viết và dữ liệu thẻ meta cho mỗi trang trong danh sách của bạn.
Cách tìm hoặc xác minh dữ liệu có cấu trúc Schema markup
Để tìm xem những trang nào đã có Schema bạn cần sử dụng các bộ lọc tùy chỉnh. Chỉ cần chọn “Configuration” –> “Custom –> “Search” –> “Add” và thêm đoạn mã bạn muốn tìm kiếm trong HTML code website. Bạn có thể xem cấu trúc dữ liệu trên trang http://schema.org
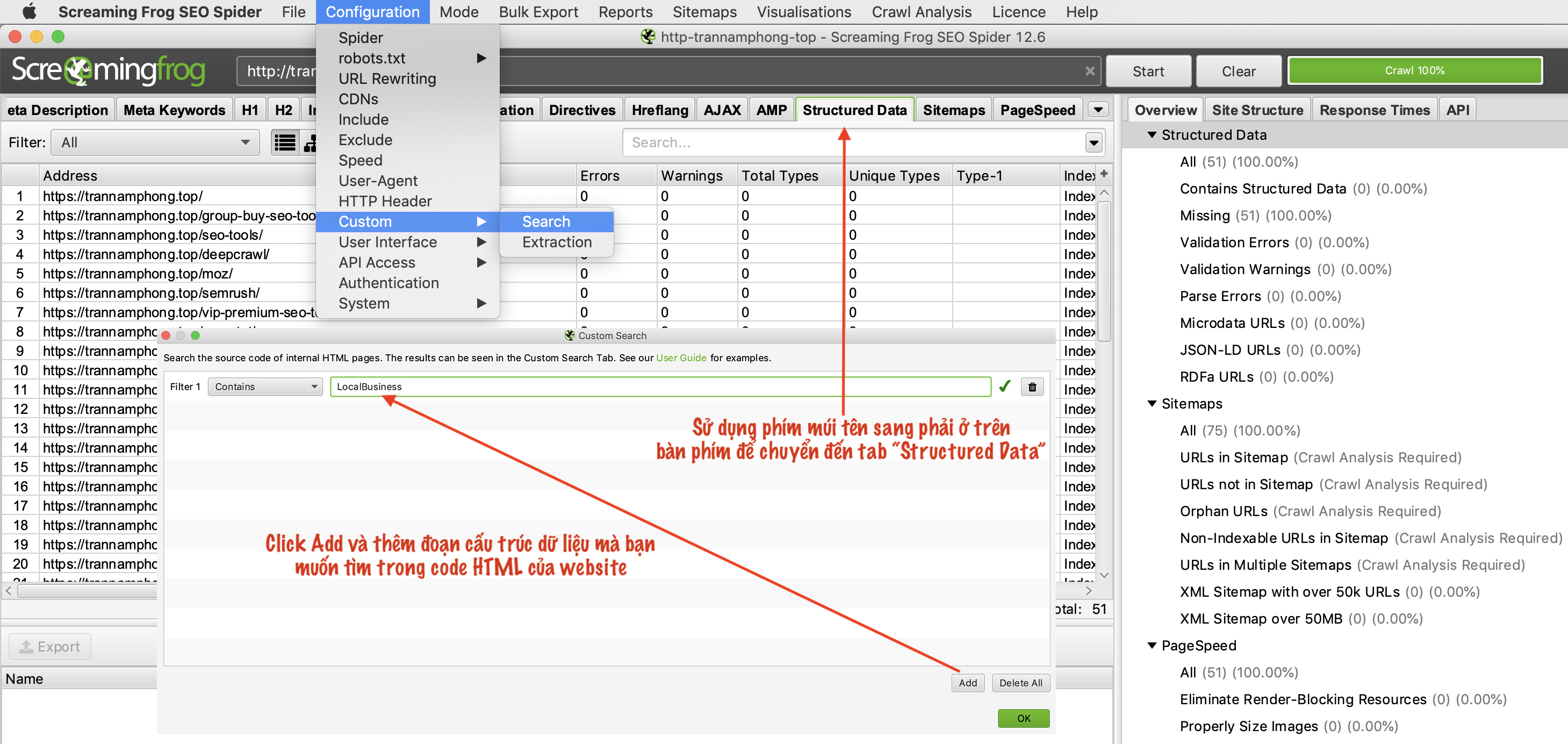
Ở ví dụ này mình tìm tất cả các trang có Schema “LocalBusiness” trên trang web Trannamphong.top
Và ở tab “Structured Data” bạn sẽ thấy những trang nào đang sử dụng LocalBusiness những trang nào không sử dụng và ở đây bạn có thể lọc Filter để biết những trang nào đang bị lỗi Schema “LocalBusiness” hay bị cảnh báo.
Bạn cũng có thể trích xuất các dữ liệu có cấu trúc bằng cách truy cập “Reports > Structured Data > Validation Errors & Warnings.”
Mẹo: Bằng cách sử dụng “Custom –> Search” bạn cũng có thể tìm Malware hoặc các đoạn mã Spam trên website.
Sử dụng “Configuration –> Custom –> Extraction” để tìm bất kỳ phần tử HTML (HTML Elements) trong code website.
Nếu bạn muốn tạo sitemap cho website thì trên thanh menu bạn chọn “Siteamps” và lựa chọn XML Sitemap”. Bạn cũng có thể kiểm tra Sitemap bằng cách chọn “Mode” –> “List” và Upload hoặc điền đường link sitemap website của bạn và nhấn Start để kiểm tra.
Xác định lý do tại sao có những bài viết không được Index và có những bài chưa được xếp hạng
Đầu tiên là bạn cần kiểm tra xem url bài viết đó có bị chặn trong files robots.txt hay có đang để thẻ noindex hay không. Tiếp theo bạn cần kiểm tra xem trang đó có phải là trang “mồ côi” hay không, nghĩa là trang đó không nhận được liên kết nội bộ từ những trang khác chỉ đến.
Trong menu “Configuration” –>”Spider” bạn nhớ click chọn vào ô “Crawl Linked XML Sitemaps”
Tiếp theo là vào “Configuration → API Access → Google Analytics” để kết nối với tài khoản Google Analytics và phân tích “Organic Traffic” để tìm các trang mồ côi (orphan pages).
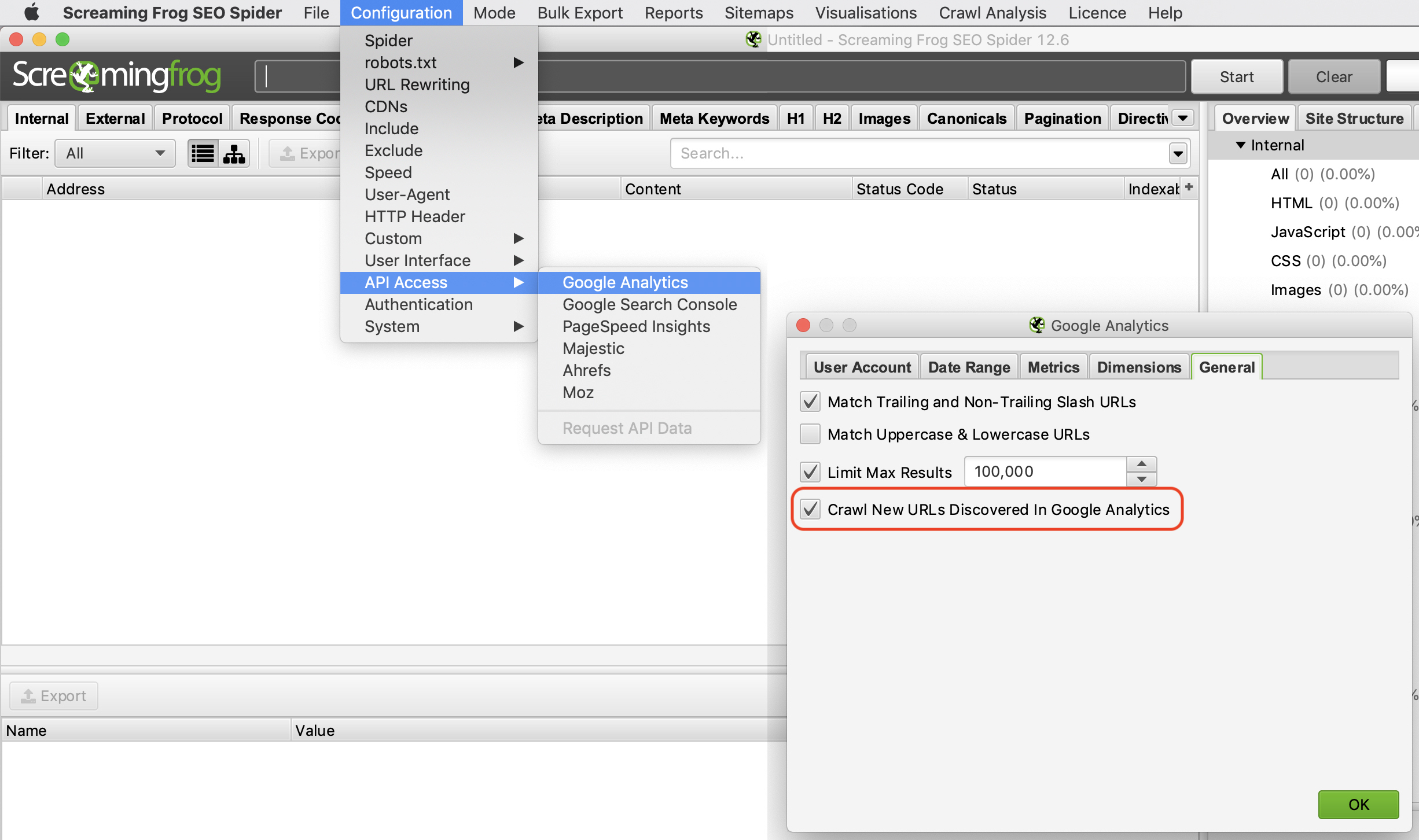
Ở tab General bạn nhớ chọn “Crawl New URLs Discovered In Google Analytics” nếu bạn muốn xem đầy đủ các URL có trong GA.
Tiếp theo là bạn cần kết nối với Google Search Console: “Configuration → API Access → Google Search Console”
Ở tab General bạn nhớ chọn “Crawl New URLs Discovered In Google Analytics” nếu bạn muốn xem đầy đủ các URL có trong GSC.
Sau khi Crawl kết thúc bạn hãy chọn “Crawl Analysis –> Start” và đợi phần mềm chạy. Sau khi chạy xong bạn có thể Export dữ liệu bằng cách chọn “Reports → Orphan Pages”
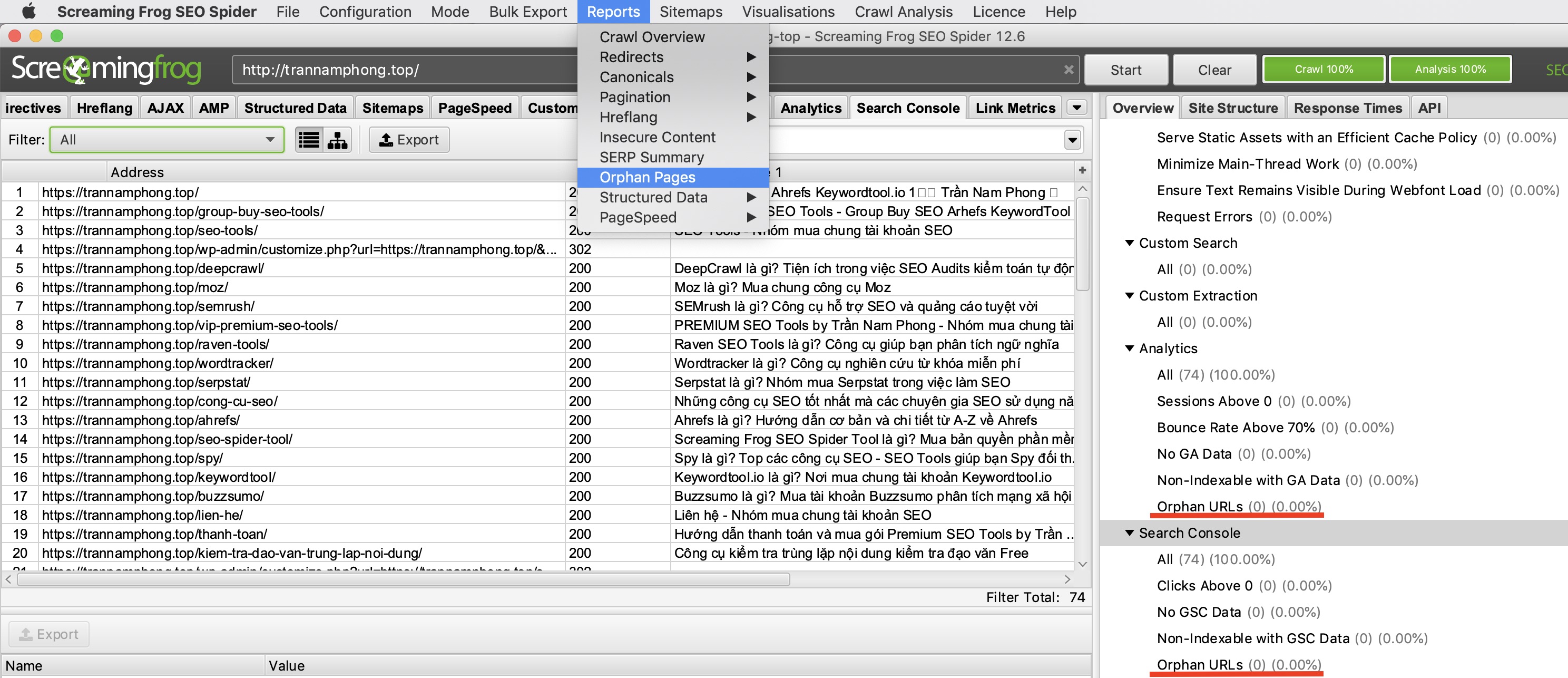
Ở đây bạn cũng có thể xem được trên website của bạn có những bài viết nào có tỷ lệ thoát trên 70%, những bài nào không được Index…
Nếu bạn không có quyền truy cập vào Google Analytics hoặc Google Search Console, bạn có thể xuất danh sách các URL muốn kiểm tra ở định dạng tệp .CSV, bằng cách sử dụng bộ lọc “HTML” ở tab “Internal” và sử dụng hàm VLOOKUP để tìm các URL chưa được Index hoặc chưa được xếp hạng.
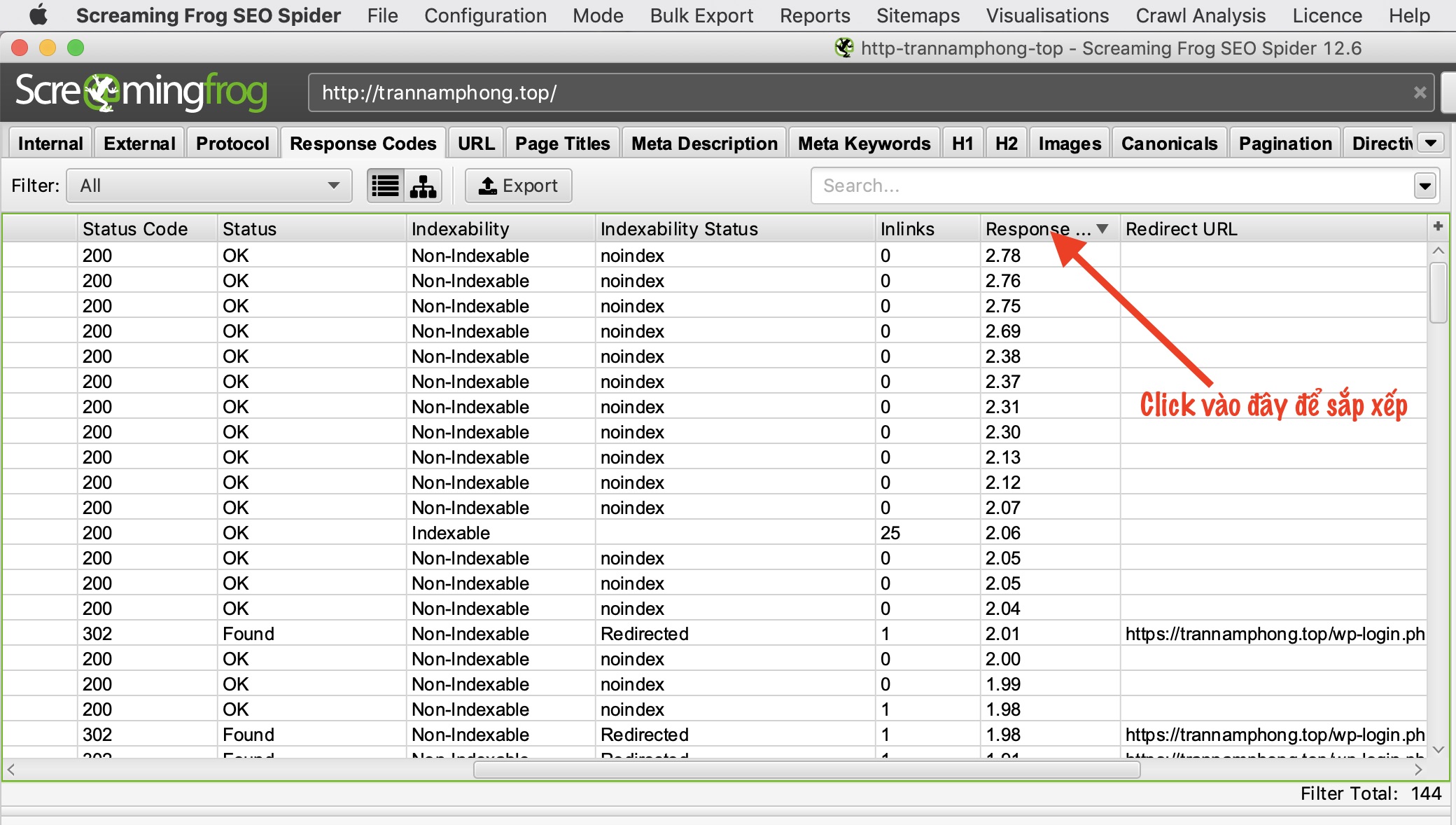
Cách tìm các trang có tốc độ Load chậm trên Website
Sau khi quét xong bạn chuyển đến tab “Response Codes” và click vào “Response Time” để sắp xếp cột thời gian phản hồi từ cao xuống thấp để tìm các trang có tốc độ tải chậm.
Tính năng viết lại hoặc thay thế tham số trong URL – URL Rewriting
Bạn chọn menu “Configuration → URL Rewriting”
Ở đây bạn có thể xóa hoặc thay đổi các tham số trong URL ví dụ như xóa 1 chữ nào đó trong URL hoặc thay đổi tên miền từ .com thành .com.vn
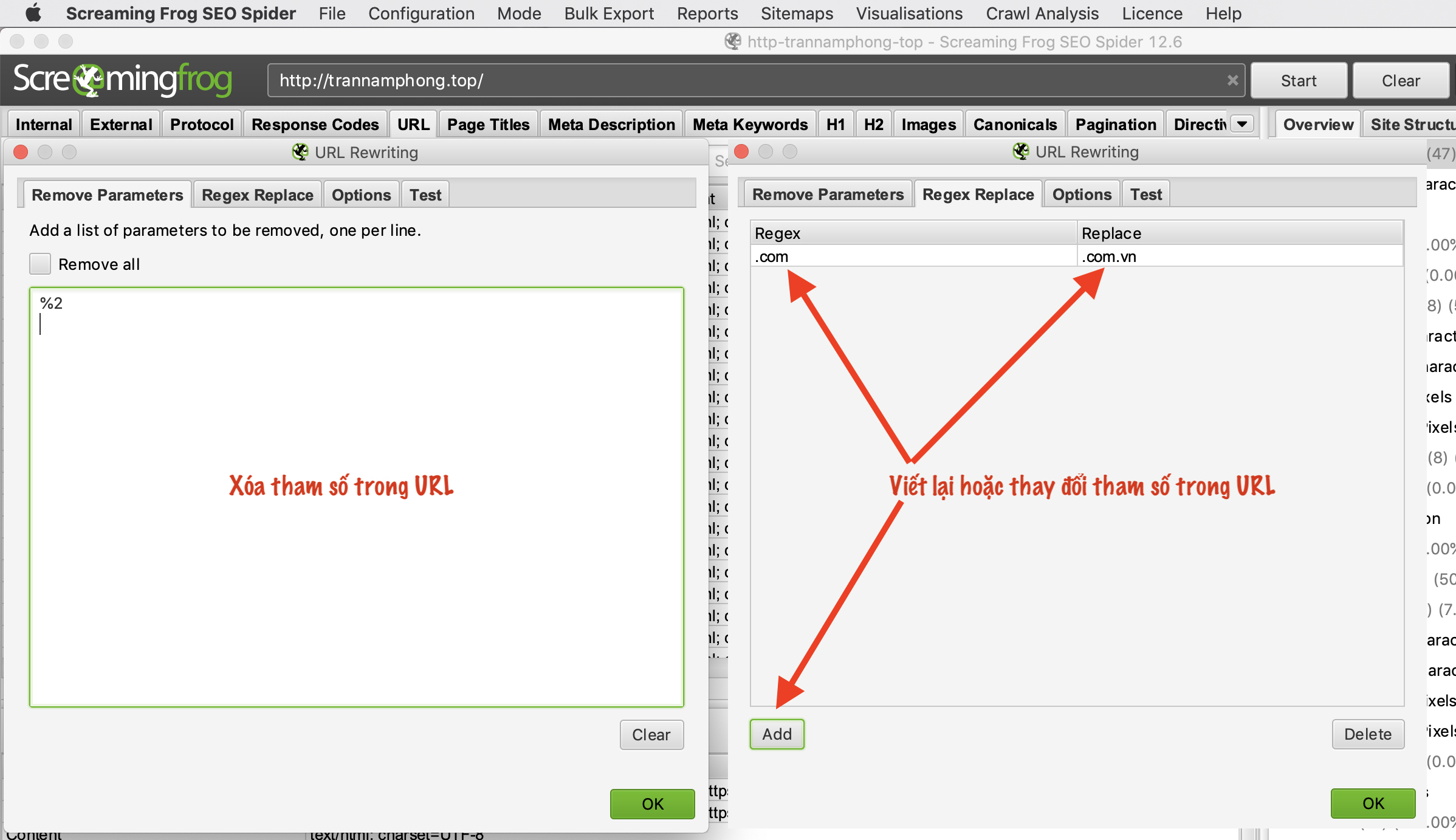
Nhấn vào tab “Test” để kiểm tra trước khi thực hiện việc thay đổi.
Làm thế nào để biết trang nào của đối thủ được đánh giá cao nhất
Nói chung, các đối thủ cạnh tranh sẽ cố gắng đặt liên kết nội bộ (Internal link) đến các bài viết có giá trị nhất của họ. Bất kỳ đối thủ cạnh tranh có tư duy SEO tốt đều đi link nội bộ đến các trang quan trọng của họ. Như vậy bạn có thể ra các trang này bằng cách thu thập dữ liệu trang web của họ, sau đó nhấn vào tab “Internal” và kéo sang bên phải để sắp xếp cột “Inlinks” theo thứ tự từ cao đến thấp để xem trang nào có nhiều liên kết nội bộ nhất. Bạn cũng có thể đánh giá thêm về “Link Score” để xem link nào được đánh giá cao.
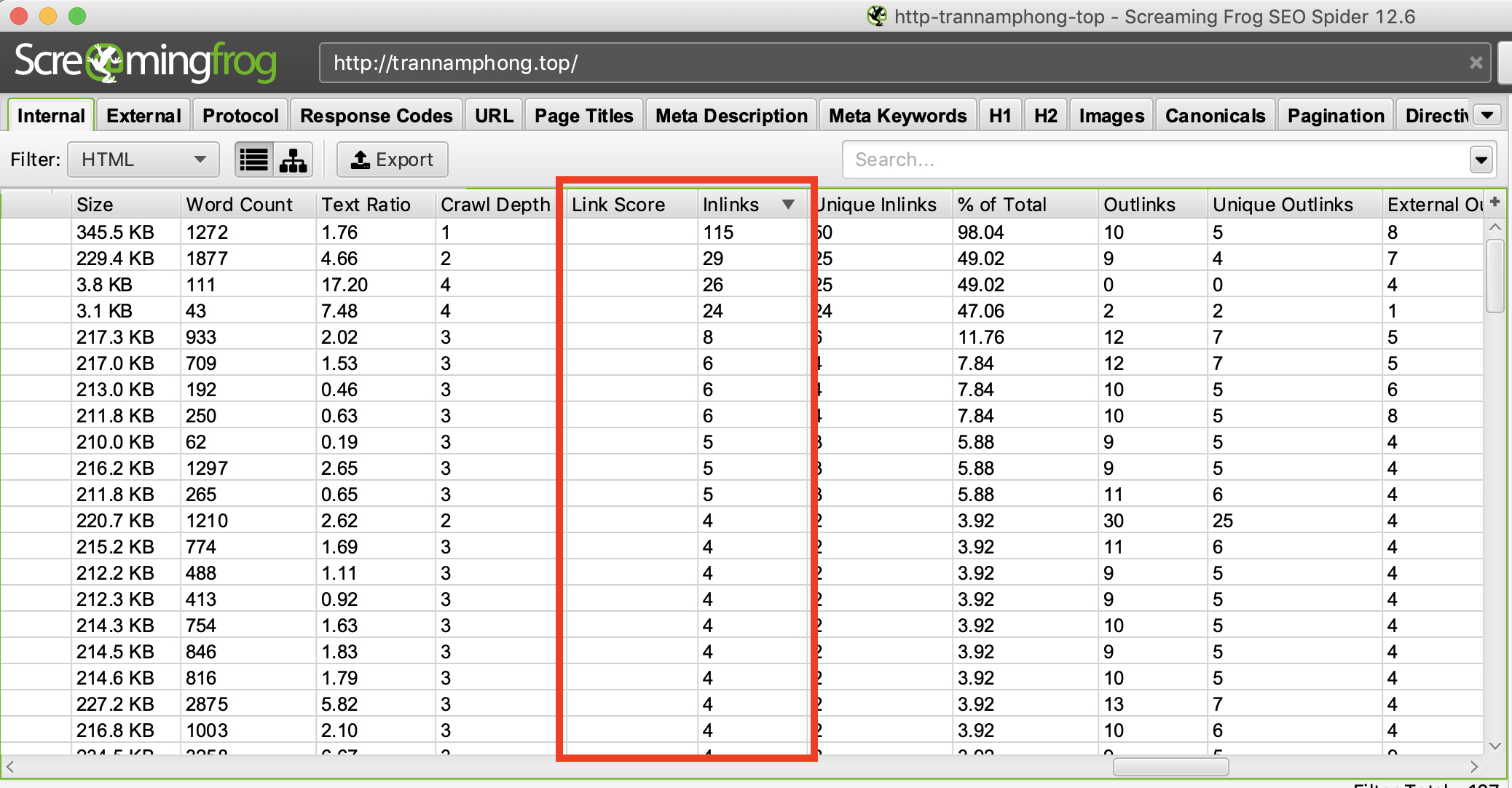
Bạn có thể sử dụng Screaming Frog để phân tích cấu trúc sơ đồ các bài viết dựa trên mô hình Topic Cluster (cụm chủ đề) lấy Pillar Page (1 bài viết chính làm trung tâm). Hãy truy cập vào menu “Visualisations” và chọn xem các đồ thị và biểu đồ ở đó.
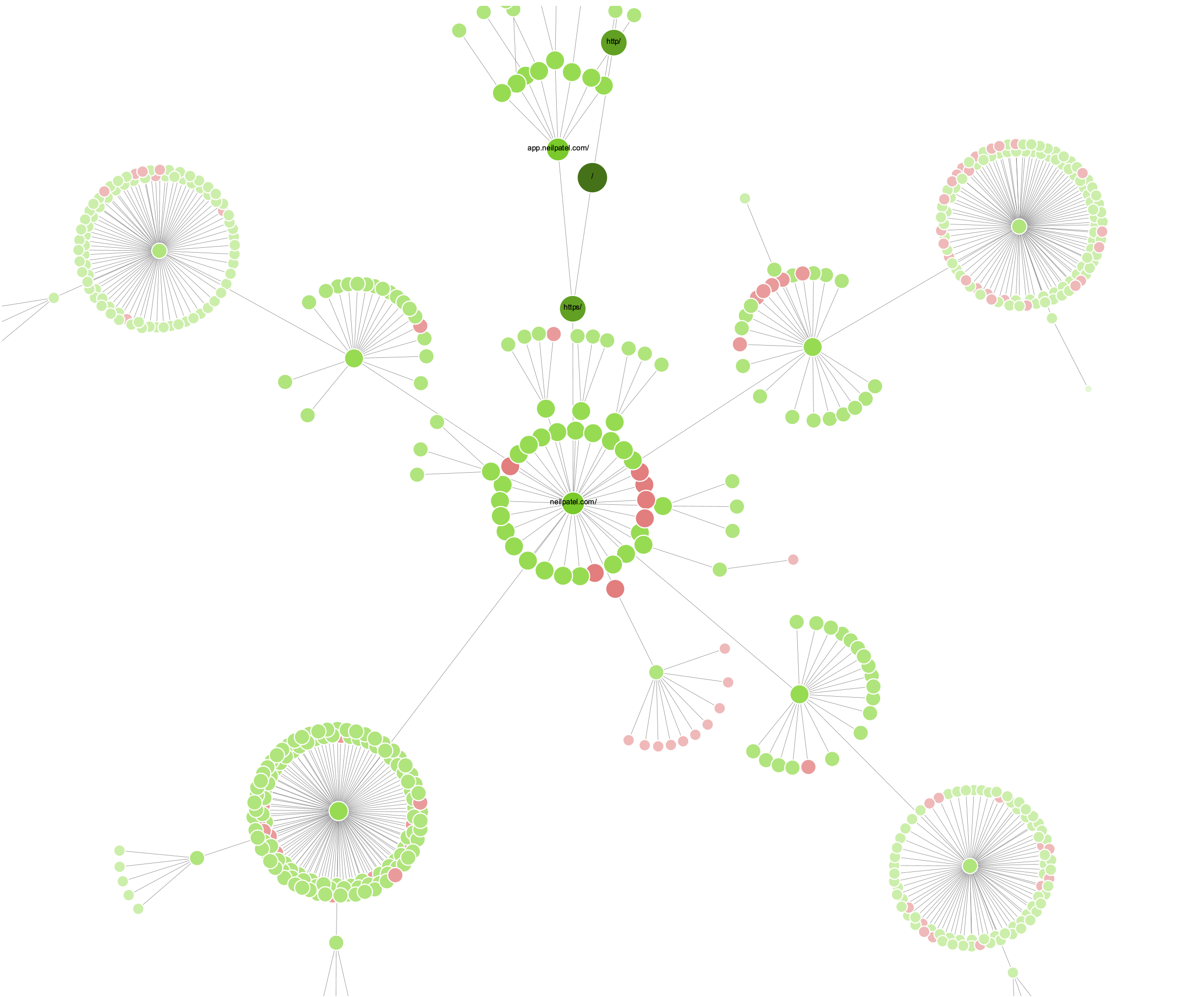
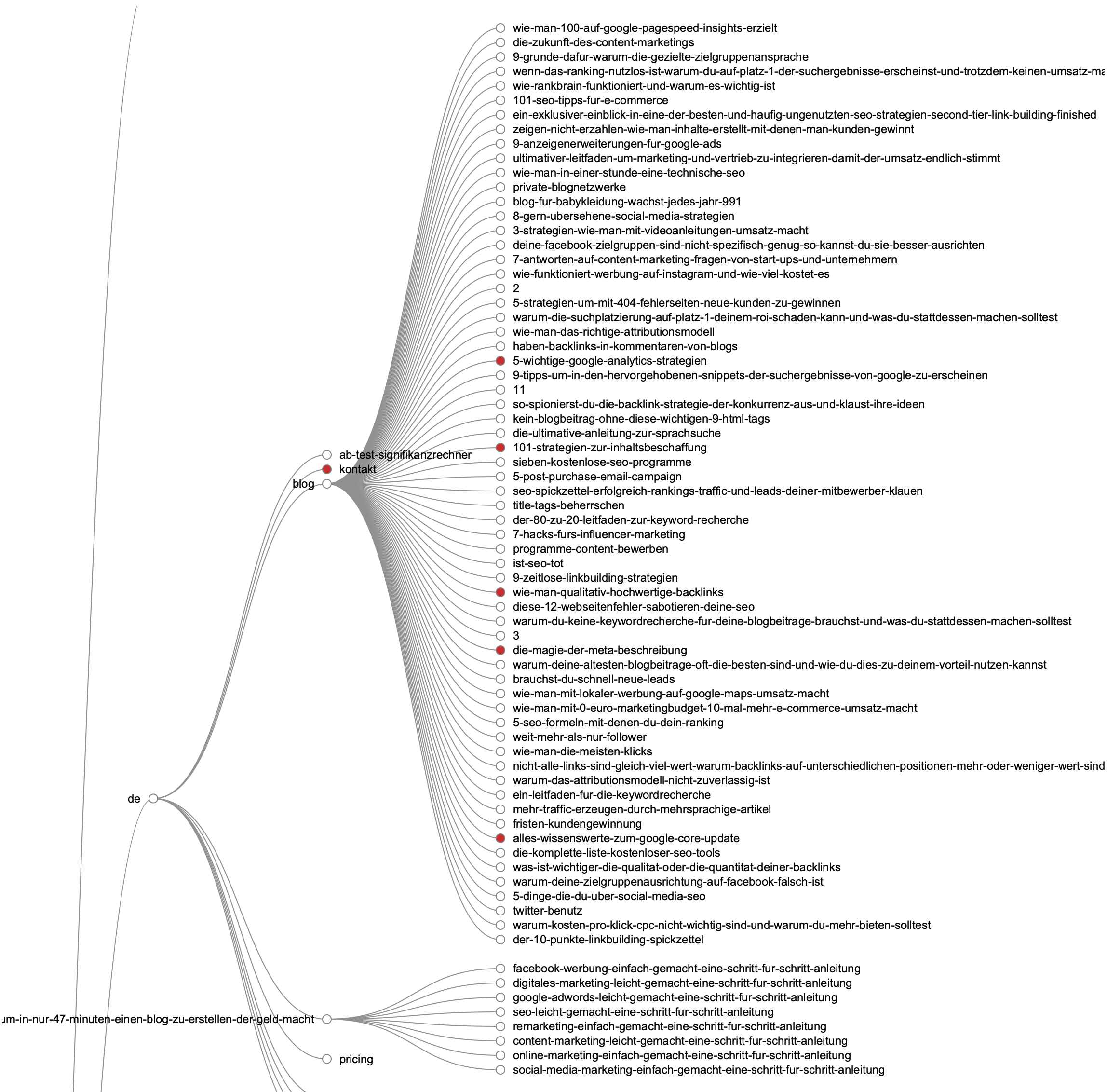
Tiếp tục phân tích Links của đối thủ
Bạn hãy chọn chọn menu “Mode” –> “List” sau đó tải lên danh sách URL mà bạn đã quét. Nhấn Start, sau khi chạy xong hãy kiểm tra mã trạng thái ở tab “Response Codes” và xem xét outbound links, link types, anchor text và nofollow trong tab “Outlinks” ở cửa sổ phía dưới cùng. Để xem thông tin ở bảng “Outlinks” bạn cần chọn URL ở cửa sổ phía trên.
Để xuất danh sách bạn chọn menu “Bulk Export –> All Outlinks”. Như vậy bạn có thể xem được các link nội bộ và link ra bên ngoài của đối thủ.
Hướng dẫn tìm văn bản neo (Anchor text) mà đối thủ sử dụng cho Link nội bộ
Trên thanh menu bạn chọn “Bulk Export” và chọn “All Anchor Text” để export ra CSV sau đó bạn có thể xem các Anchor text mà đối thủ sử dụng cho Internal link.
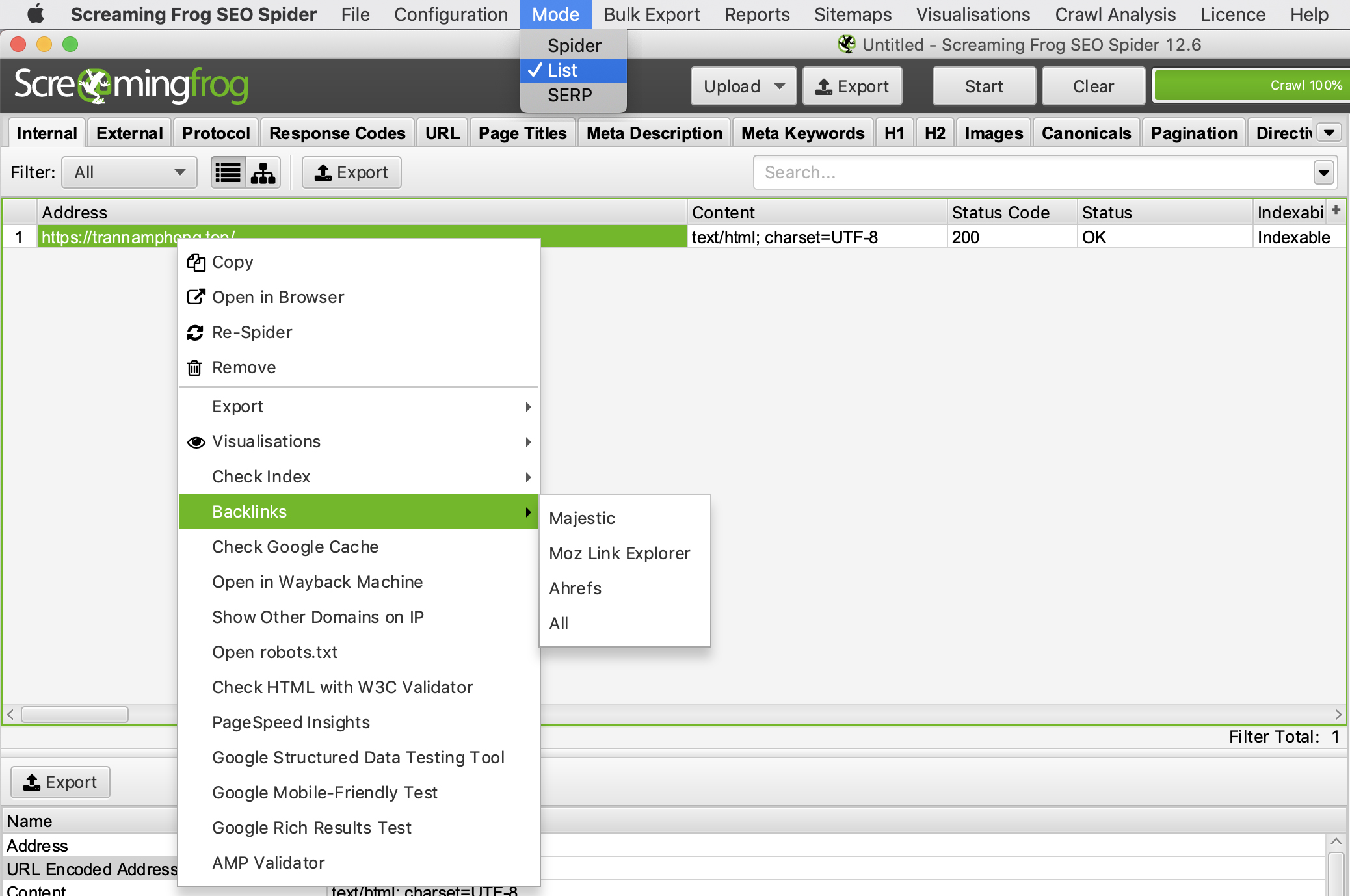
Sử dụng Screaming Frog để xác minh Backlinks và xem lại Anchor text
Ahrefs là công cụ SEO khá tốt có thể làm được việc này nhưng nếu bạn muốn sử dụng Screaming Frog thì bạn có thể Export danh sách Backlinks từ Tool nào đó như GSC hay Ahrefs sau đó chuyển chế độ sang “Mode –> List” và sau đó lại trích xuất toàn bộ danh sách outbound links bằng cách chọn menu “Bulk Export –> All Outlinks” sau đó sử dụng tính năng lọc ở cột “Destination” để xem các Backlinks đó đang đặt Anchor text là gì.
Nếu bạn chưa có tài khoản Ahrefs thì bạn cần mua chung Ahrefs tại website trannamphong.top. Hiện tại chúng tôi đang cho thuê tài khoản mua chung Ahrefs sử dụng nhanh và ổn định, đầy đủ tính năng.
Sử dụng Screaming Frog để dọn dẹp gỡ bỏ và Audit Backlinks
Chọn “Mode –> List” và Upload Backlinks của bạn lên và nhấn Start sau đó chọn tab “Custom” để xem các trang đang liên kết với bạn.
Kết bài
Cuối cùng, tôi hy vọng rằng bài viết hướng dẫn này cung cấp cho bạn ý tưởng tốt hơn về việc sử dụng Screaming Frog để phục vụ cho công việc của bạn. Nó đã giúp tôi tiết kiệm khá nhiều thời gian, vì vậy tôi hy vọng rằng nó cũng giúp ích cho bạn!